Airbnb - WordCloud and Some Other Exploratory Analysis
Introduction
In this project, we will show some visualizations of the Airbnb listings in Singapore. The data can be obtained from AirBnB insideairbnb.com; it was originally scraped from airbnb.com.
Exploratory Data Analysis
To begin with our project, we are going to load the listings.csv dataset and get and explore it.
The first step is some data cleaning.
Data Wrangling
We will use the clean_names() function from the janitor library to clean the name of the columns. This will turn upper cases into lower cases, delete parentheses, and replace spaces with underscores.
# Clean names
airbnb <- airbnb %>%
clean_names()We can now take a look at our data
# Take a glimpse - airbnb
glimpse(airbnb)## Rows: 7,323
## Columns: 106
## $ id <dbl> 49091, 50646, 56334, 7...
## $ listing_url <chr> "https://www.airbnb.co...
## $ scrape_id <dbl> 2.020062e+13, 2.020062...
## $ last_scraped <date> 2020-06-22, 2020-06-2...
## $ name <chr> "COZICOMFORT LONG TERM...
## $ summary <chr> NA, "Fully furnished b...
## $ space <chr> "This is Room No. 2.(a...
## $ description <chr> "This is Room No. 2.(a...
## $ experiences_offered <chr> "none", "none", "none"...
## $ neighborhood_overview <chr> NA, "The serenity & qu...
## $ notes <chr> NA, "Accommodation has...
## $ transit <chr> NA, "Less than 400m fr...
## $ access <chr> NA, "Kitchen, washing ...
## $ interaction <chr> NA, "We love to host p...
## $ house_rules <chr> "No smoking indoors. P...
## $ thumbnail_url <lgl> NA, NA, NA, NA, NA, NA...
## $ medium_url <lgl> NA, NA, NA, NA, NA, NA...
## $ picture_url <chr> "https://a0.muscache.c...
## $ xl_picture_url <lgl> NA, NA, NA, NA, NA, NA...
## $ host_id <dbl> 266763, 227796, 266763...
## $ host_url <chr> "https://www.airbnb.co...
## $ host_name <chr> "Francesca", "Sujatha"...
## $ host_since <date> 2010-10-20, 2010-09-0...
## $ host_location <chr> "singapore", "Singapor...
## $ host_about <chr> "I am a private tutor ...
## $ host_response_time <chr> "within an hour", "N/A...
## $ host_response_rate <chr> "100%", "N/A", "100%",...
## $ host_acceptance_rate <chr> "N/A", "N/A", "N/A", "...
## $ host_is_superhost <lgl> FALSE, FALSE, FALSE, F...
## $ host_thumbnail_url <chr> "https://a0.muscache.c...
## $ host_picture_url <chr> "https://a0.muscache.c...
## $ host_neighbourhood <chr> "Woodlands", "Bukit Ti...
## $ host_listings_count <dbl> 2, 1, 2, 8, 8, 8, 8, 4...
## $ host_total_listings_count <dbl> 2, 1, 2, 8, 8, 8, 8, 4...
## $ host_verifications <chr> "['email', 'phone', 'f...
## $ host_has_profile_pic <lgl> TRUE, TRUE, TRUE, TRUE...
## $ host_identity_verified <lgl> FALSE, FALSE, FALSE, T...
## $ street <chr> "Singapore, Singapore"...
## $ neighbourhood <chr> "Woodlands", "Bukit Ti...
## $ neighbourhood_cleansed <chr> "Woodlands", "Bukit Ti...
## $ neighbourhood_group_cleansed <chr> "North Region", "Centr...
## $ city <chr> "Singapore", "Singapor...
## $ state <chr> NA, NA, NA, NA, NA, NA...
## $ zipcode <chr> "730702", "589664", NA...
## $ market <chr> "Singapore", "Singapor...
## $ smart_location <chr> "Singapore", "Singapor...
## $ country_code <chr> "SG", "SG", "SG", "SG"...
## $ country <chr> "Singapore", "Singapor...
## $ latitude <dbl> 1.44255, 1.33235, 1.44...
## $ longitude <dbl> 103.7958, 103.7852, 10...
## $ is_location_exact <lgl> TRUE, TRUE, TRUE, TRUE...
## $ property_type <chr> "Apartment", "Apartmen...
## $ room_type <chr> "Private room", "Priva...
## $ accommodates <dbl> 1, 2, 1, 6, 3, 3, 6, 1...
## $ bathrooms <dbl> 1.0, 1.0, 1.0, 1.0, 0....
## $ bedrooms <dbl> 1, 1, 1, 2, 1, 1, 1, 1...
## $ beds <dbl> 1, 1, 1, 3, 1, 2, 7, 1...
## $ bed_type <chr> "Real Bed", "Real Bed"...
## $ amenities <chr> "{TV,\"Cable TV\",Inte...
## $ square_feet <dbl> 0, NA, 0, 205, NA, NA,...
## $ price <chr> "$84.00", "$80.00", "$...
## $ weekly_price <chr> NA, "$400.00", NA, NA,...
## $ monthly_price <chr> "$1,048.00", "$1,600.0...
## $ security_deposit <chr> NA, NA, NA, "$279.00",...
## $ cleaning_fee <chr> NA, NA, NA, "$56.00", ...
## $ guests_included <dbl> 1, 2, 1, 4, 1, 1, 4, 1...
## $ extra_people <chr> "$14.00", "$20.00", "$...
## $ minimum_nights <dbl> 180, 90, 6, 90, 90, 90...
## $ maximum_nights <dbl> 360, 730, 14, 1125, 11...
## $ minimum_minimum_nights <dbl> 180, 90, 6, 90, 90, 90...
## $ maximum_minimum_nights <dbl> 180, 90, 6, 90, 90, 90...
## $ minimum_maximum_nights <dbl> 360, 730, 14, 1125, 11...
## $ maximum_maximum_nights <dbl> 360, 730, 14, 1125, 11...
## $ minimum_nights_avg_ntm <dbl> 180, 90, 6, 90, 90, 90...
## $ maximum_nights_avg_ntm <dbl> 360, 730, 14, 1125, 11...
## $ calendar_updated <chr> "73 months ago", "71 m...
## $ has_availability <lgl> TRUE, TRUE, TRUE, TRUE...
## $ availability_30 <dbl> 30, 30, 30, 30, 30, 30...
## $ availability_60 <dbl> 60, 60, 60, 60, 60, 60...
## $ availability_90 <dbl> 90, 90, 90, 90, 90, 90...
## $ availability_365 <dbl> 365, 365, 365, 365, 36...
## $ calendar_last_scraped <date> 2020-06-22, 2020-06-2...
## $ number_of_reviews <dbl> 1, 18, 20, 20, 24, 48,...
## $ number_of_reviews_ltm <dbl> 0, 0, 0, 8, 4, 13, 6, ...
## $ first_review <date> 2013-10-21, 2014-04-1...
## $ last_review <date> 2013-10-21, 2014-12-2...
## $ review_scores_rating <dbl> 94, 91, 98, 89, 83, 88...
## $ review_scores_accuracy <dbl> 10, 9, 10, 9, 8, 9, 9,...
## $ review_scores_cleanliness <dbl> 10, 10, 10, 8, 8, 9, 8...
## $ review_scores_checkin <dbl> 10, 10, 10, 9, 9, 9, 9...
## $ review_scores_communication <dbl> 10, 10, 10, 10, 9, 9, ...
## $ review_scores_location <dbl> 8, 9, 8, 9, 8, 9, 9, 1...
## $ review_scores_value <dbl> 8, 9, 9, 9, 8, 9, 8, 1...
## $ requires_license <lgl> FALSE, FALSE, FALSE, F...
## $ license <lgl> NA, NA, NA, NA, NA, NA...
## $ jurisdiction_names <lgl> NA, NA, NA, NA, NA, NA...
## $ instant_bookable <lgl> FALSE, FALSE, FALSE, T...
## $ is_business_travel_ready <lgl> FALSE, FALSE, FALSE, F...
## $ cancellation_policy <chr> "flexible", "moderate"...
## $ require_guest_profile_picture <lgl> TRUE, FALSE, TRUE, FAL...
## $ require_guest_phone_verification <lgl> TRUE, TRUE, TRUE, TRUE...
## $ calculated_host_listings_count <dbl> 2, 1, 2, 8, 8, 8, 8, 3...
## $ calculated_host_listings_count_entire_homes <dbl> 0, 0, 0, 0, 0, 0, 0, 0...
## $ calculated_host_listings_count_private_rooms <dbl> 2, 1, 2, 8, 8, 8, 8, 3...
## $ calculated_host_listings_count_shared_rooms <dbl> 0, 0, 0, 0, 0, 0, 0, 0...
## $ reviews_per_month <dbl> 0.01, 0.24, 0.18, 0.19...
It seems that from the 106 variables, 47 are character, 5 are date type, 15 are logical and 39 are numeric. After extensive analysis on each variable, we decided to include a minimum set that goes as follows:
price: cost per nightcleaning_fee: cleaning feeextra_people: charge for having 1 extra personproperty_type: type of accommodationroom_type:- Entire home/apt
- Private room
- Shared room
number_of_reviews: Total reviews for the listingreview_scores_rating: Average review scorelongitude,latitude: geographical coordinates to help us locate the listingneighbourhood_cleansed: three variables on a few major neighbourhoods in each city
Other than these, we also decided to include the following to improve our analysis:
minimum_nightshost_is_superhosthost_has_profile_pichost_identity_verifiedinstant_bookablehost_response_rateinstant_bookableneighbourhood_group_cleansedguests_included- ’
We will create a subset by creating vectors with these variables and then select them using
select(). The methodall_of()will come in handy to select columns from within a vector. We will store this new dataframe in an object calledairbnb_cleaned.
sum(is.na(airbnb$price))## [1] 0# Establish ideal variable names in a vector
ideal_vars<- c("price",
"cleaning_fee",
"extra_people",
"property_type",
"room_type",
"number_of_reviews",
"review_scores_rating",
"longitude",
"latitude",
"neighbourhood_cleansed")
# Create vector with extra variables to select
extra_vars<- c("minimum_nights",
"host_is_superhost",
"host_has_profile_pic",
"host_identity_verified",
"instant_bookable",
"neighbourhood_group_cleansed",
"guests_included",
"bathrooms",
"bedrooms",
"beds",
"cancellation_policy",
"review_scores_location",
"last_review",
"is_location_exact",
"amenities",
"availability_365",
"calculated_host_listings_count",
"description",
"name")
# Select ideal variables
airbnb_cleaned <- airbnb %>%
# all_of selects vars in a vector
select(all_of(c(ideal_vars, extra_vars))) # c(v1,v2) will combine both vectors into one
For the former point, we will use the parse_number() function to strip the number and convert into a numerical value. For the latter, it’s a bit more complicated. While discussing what should NA be replaced by could take hours, it is important to analyze the context. When discussing a cleaning_fee for AirBnB, we assume that anyone who has a specific fee will include it - therefore, the NA should be considered as 0. We will proceed to do a similar thing with the logical variables - we will replace those by FALSE, as we understand that if there is no information about being superhost, having identity verified and having a profile picture (attributes that should be easy to analyse) then those were probably FALSE. On the other hand, review_scores_rating will remain as NA, as replacing them by 0 will just affect the mean of the scores.
# Save into new object
airbnb_cleaned <- airbnb_cleaned %>%
# Parse numbers and strip the $
mutate(price = parse_number(price),
cleaning_fee = parse_number(cleaning_fee),
extra_people = parse_number(extra_people),
# Replace NA with 0
cleaning_fee = case_when(
is.na(cleaning_fee) ~ 0,
TRUE ~ cleaning_fee),
# Replace host_is_superhost missing with "FALSE"
host_is_superhost = case_when(
is.na(host_is_superhost) ~ FALSE,
TRUE ~ host_is_superhost),
# Replace host_has_profile_ic missing with "FALSE"
host_has_profile_pic = case_when(
is.na(host_has_profile_pic) ~ FALSE,
TRUE ~ host_has_profile_pic),
# Replace host_identity_verified missing with "FALSE"
host_identity_verified = case_when(
is.na(host_identity_verified) ~ FALSE,
TRUE ~ host_identity_verified)
)
We can appreciate that now cleaning_fee has 0 n_missing - being part of the numerical variables. All logical variables have zero missing values as well.
We will add a new variable logical that will tell us whether the flat has a pool or a gym.
Some Visualizations
We are going to see the most popular words used for the most expensive listings on Airbnb, by creating a word cloud of top 100 Airbnb names by price, First, we select the top 100 listings by price per night.
airbnb_description <- airbnb_cleaned %>%
top_n(100, wt=price)The following code to create a WordCloud was inspired by [How to Generate Word Clouds Article on www.towardsdatascience.com] (https://towardsdatascience.com/create-a-word-cloud-with-r-bde3e7422e8a), by Céline Van den Rul and by [How to Create a Word Cloud in R by Jyotsna Vadakkanmarveettil on https://www.jigsawacademy.com/] (https://www.jigsawacademy.com/how-to-create-a-word-cloud-in-r/)
First, we cleaned the text. Next, we create a matrix with the number of occurances of these words in the top 100 listings’ names. Finally, we create the word cloud.
#Convert data to corpus so to use tm package
text1<-Corpus(VectorSource(airbnb_description$name))
#Convert text to lower
text2<-tm_map(text1,tolower)
#Remove space
text2<-tm_map(text2,stripWhitespace)
#Remove numbers
text2<-tm_map(text2,removeNumbers)
#Remove punctuations
text2<-tm_map(text2,removePunctuation)
#Remove stopwords such as 'the, from'
text2<-tm_map(text2,removeWords, stopwords('english'))
#Creates a TDM
tdm_text<-TermDocumentMatrix(text2)
#Convert this into a matrix format
TDM1<-as.matrix(tdm_text)
#Created vector in descending of apperances in text
v = sort(rowSums(TDM1), decreasing = TRUE)
#Created dataframes with number names and number of appereances
dataword<- data.frame(word = names(v),freq=v)
#set seed to obtain same results
seed=1055
wordcloud(words = dataword$word,
#number of occurances
freq = dataword$freq,
#set scale cause otherwise some words won't fit
scale=c(1.2,0.5),
#maximum number of words displayed
max.words=50,
#displayed in specific order
random.order=FALSE,
#rotation
rot.per=0.35,
use.r.layout=FALSE,
#use this color palette
colors=brewer.pal(8, 'Dark2'))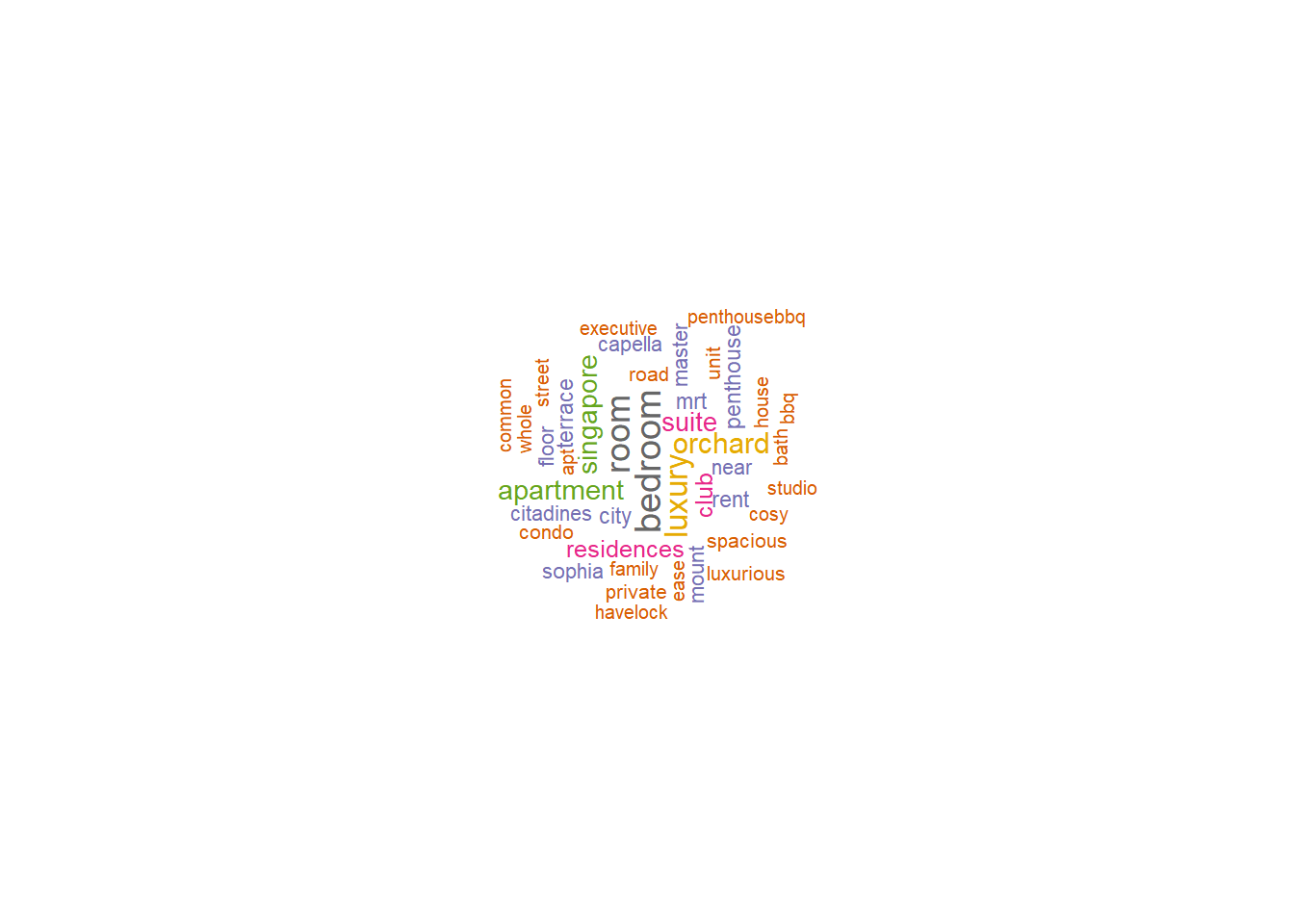
We could see that among the most popular words to use for expensive Airbnb there are bedrooms, orchard, residences, but also predictable words such as luxury/luxurious, spacious, and private, and cozy. We notice a tendecy for terrace, orchard that makes us thing that the most expensive listings are houses.
##Most popular neighbouthood
We are going to look at the average price per neighbourhood and compare that with the review for the location in order to make a sense which are the best areas in Singapore.
# Create data frame
location_price <- airbnb_cleaned%>%
# Group by
group_by(neighbourhood_group_cleansed) %>%
# Summarise
summarise(neigh_count= n(), # Count
# Calculate median
neigh_median_price=median(price),
# Calculate Mean of scores (drop NAs)
review_score_group=mean(review_scores_location, na.rm=TRUE))## `summarise()` ungrouping output (override with `.groups` argument)# Plot results
ggplot(location_price,
aes(x=review_score_group,
y=neigh_median_price,
label= neighbourhood_group_cleansed, fill='red')) +
# Add scatterplot
geom_point(aes(size= neigh_count), pch=21) +
# Add text
geom_text(aes(label=neighbourhood_group_cleansed), hjust=-0.07, vjust=+0.05)+
#Expand the plot so we can see all text
expand_limits(x = 9.75)+
guides(size = guides(title= "Count of properties", fill=FALSE)) +
# Add labels
labs(title="Which region is desirable?",
subtitle = "Figure 1.8",
x="Review for location",
y="Average price per neighbourhood",
caption = "Source: Inside Airbnb http://insideairbnb.com/index.html")+
theme_bw()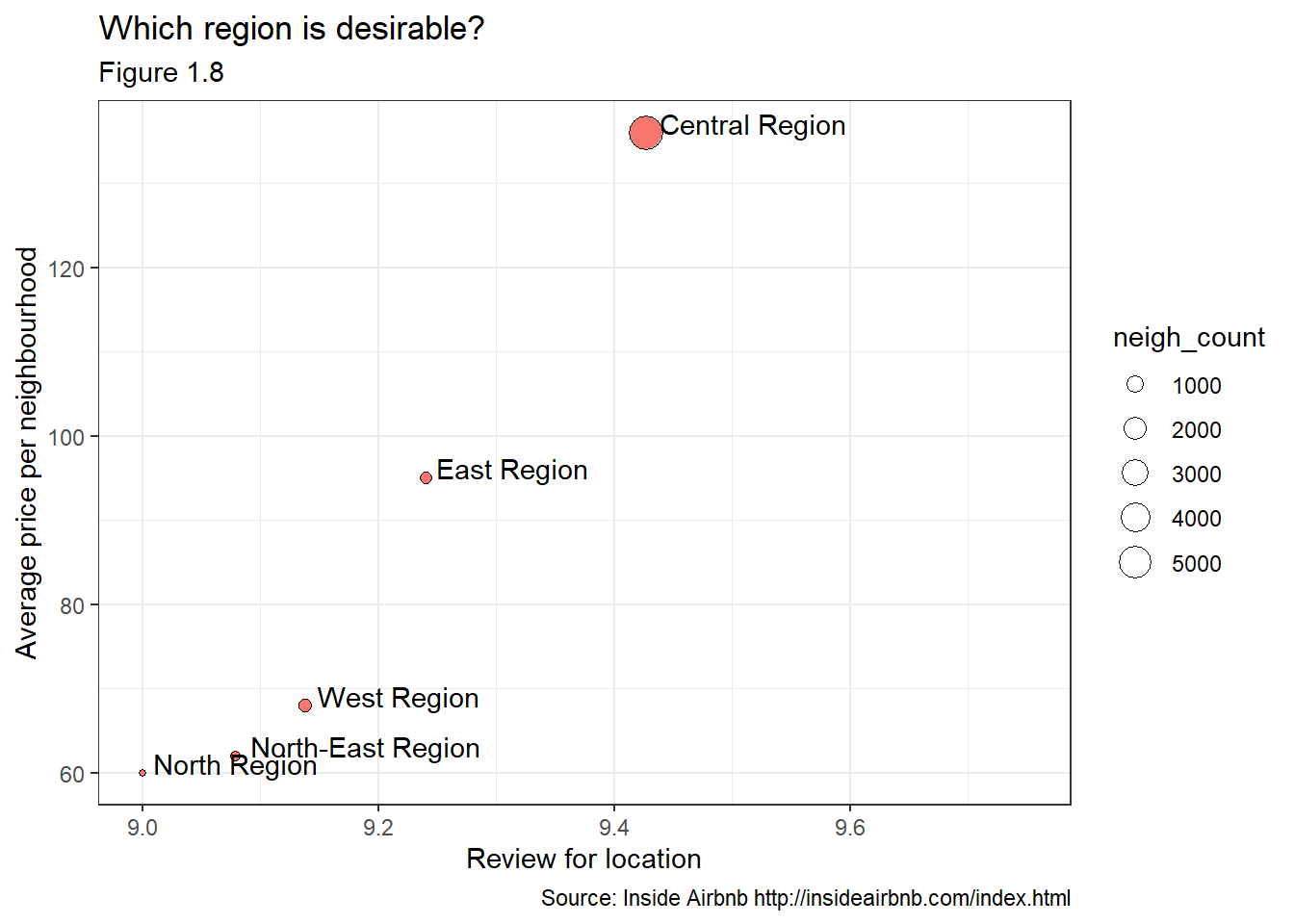
It seems that a very desirable place to stay is the Center, where there are a lots of Airbnb listings. Also, it seems that people dont like staying as much in the North region. That being said, it seems that the review for location is correlated with the average price for each neighborhood.
#### Exact Location
After seeing that some neighbourhoods are more expensive and more liked than others, we can conlude that location matters. But this location needs to be exact? We are going to look at whether Airbnb that show exact location have higher prices, by performing a hypothesis testing.
**H0**: Exact location does not have an influence on the price
**H1**: Exact location does have an influence on the price.
First, we plot a boxplot of the 2 means.
```r
# Create ggplot object
exactlocation_book_price <- ggplot(airbnb_cleaned, aes(is_location_exact,
price)) +
# Add boxplot
geom_boxplot() +
# Add labels
labs(title = "ExactLocation vs Price - How is it affected?",
x = "Exact Location",
y = "Price $") +
scale_y_log10()
# Show plot
exactlocation_book_price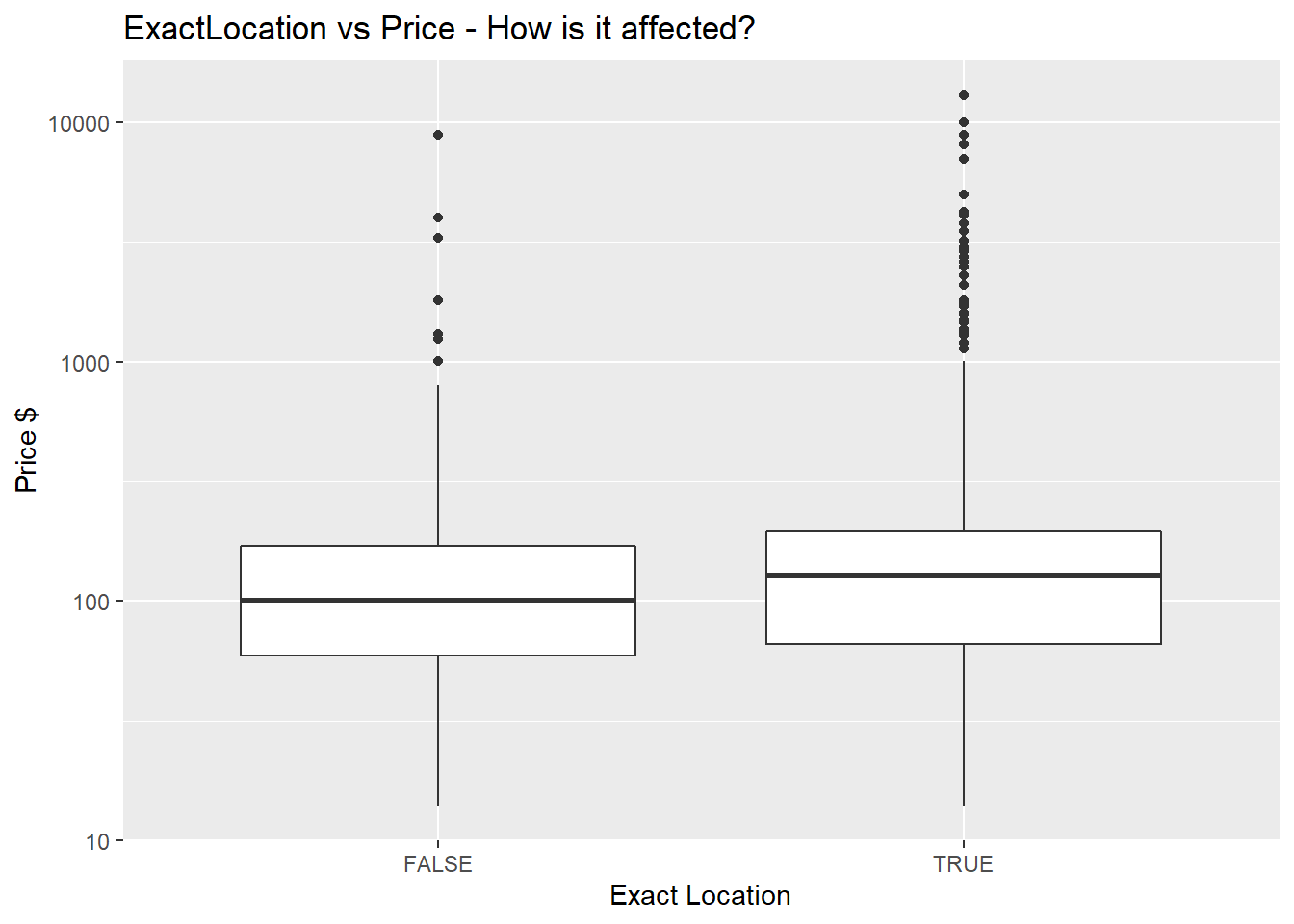
From the boxplot, we can see that there is some difference in mean. We need to further investigate that using hypothesis testing.
airbnb_cleaned %>%
#Group by
group_by(is_location_exact) %>%
#Filter out the NA
filter(!is.na(is_location_exact)) %>%
#Mean
summarise(mean_price = mean(price, na.rm = TRUE),
#SD
sd_price = sd(price, na.rm=TRUE),
#Count
count = n(),
#SE
se_price = sd_price/sqrt(count),
#T critical
t_critical = qt(0.975, count-1),
#Lower and Upper Confidence
lower = mean_price - t_critical * se_price,
upper = mean_price + t_critical * se_price
)## `summarise()` ungrouping output (override with `.groups` argument)| is_location_exact | mean_price | sd_price | count | se_price | t_critical | lower | upper |
|---|---|---|---|---|---|---|---|
| FALSE | 145 | 289 | 1478 | 7.51 | 1.96 | 131 | 160 |
| TRUE | 183 | 521 | 5845 | 6.81 | 1.96 | 170 | 197 |
#The two intervals overlap, so we have to run a t test
t.test(price ~ is_location_exact, data = airbnb_cleaned)##
## Welch Two Sample t-test
##
## data: price by is_location_exact
## t = -3.761, df = 4190.5, p-value = 0.0001716
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -58.02863 -18.26053
## sample estimates:
## mean in group FALSE mean in group TRUE
## 145.3146 183.4592
The confidence intervalus do not overlap, an indicator that we reject the null hyphotesis. Therefore we reject the null hypothesis that there is no significant difference between the price of an apartment showing the exact location and one that is not.